Introduction
Il semble possible aujourd’hui d’avoir son llm local et de faire un RAG
Le projet se base sur Neo4j pour stocker des documents entreprise , ollama et Qwen 3.5 comme llm
L’IHM est développée en python avec les lib fastapi, graph.js + jinja2 + modèle de synthèse vocal utilisant cuda, faster_whisper
Ca peut sembler curieux mais installer un LLM est aussi simple qu’utiliser docker.
Vous installez ollama et vous trouvez des commandes commandes comme pull push launch run stop…
Bon au niveau administration, ça ne vous enlève pas de configurer cuda et les librairies nvidia.
Où trouver son LLM ?
Hugging face
C’est le doctissimo du llm
Exemple Qwen: boite chinoise (Alibaba) qui fait des modèles proches de deepseek
variation de modèles
Il n’y a quasiment pas de modèle open source. licence open weight
VL: Vision Language , sait lire des images
knowledge cutoff: date limite d’apprentissage
Du coup ça appelle internet pour se compléter
Nombre de paramètres: exprimé en milliards
MoE: mixxture of experts = combiner plusieurs modèles experts
- est appelé sur une zone expert et pas l’ensemble
- exemple qwen3.5-122B-10B modèle de 122 milliards qui limitera à une zone de 10 milliards
Taille de contexte: en milliers de token : qwen 3.5 à 260k tokens.
Exemple tokenizer va donner le nombre de token pour uyn texte
quantization: fp8: modèle GPU récent
NFP4: quantization virgule flottante 4 bits
fp32: 4 octets du coup, training
La quantization consiste à réduire la précision des poids d’un modèle pour diminuer sa taille et accélérer son exécution.
La préparation de l’environnement
J’ai créé une VM avec incus sur mon serveur Ubuntu.
Propriétés principales:
- 512GB RAM
- GPU RTX1650 4GB
- GPU RTX5070 12GB
- des disques en raid 5 pour 10TB
- 2 disques SSD suplémentaires 1TB
Sur le papier, le RAG consomme 100Gb ram et ce TP utilise les 2 cartes GPU.
- Qwen3.5-7B occupe 8GB
- le transformer 1.5GB
- L’audio 3.1GB
- environ 100Gb de RAM
Fonctionnalités principales
Interface Web Interactive : Une application web simple et réactive.
Entrée Vocale : Un bouton « micro » pour dicter les questions.
RAG Conversationnel : Le système garde en mémoire le contexte de la conversation.
Base de Connaissances sur Graphe : Les documents sont stockés et interrogés dans une base de données Neo4j.
Sécurité par Rôles : L’accès aux documents est filtré en fonction du rôle de l’utilisateur.
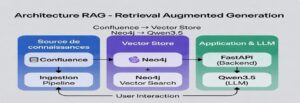
2. Architecture et Arborescence du Projet
Le projet est organisé de manière logique, séparant l’ingestion des données, l’API backend et l’interface frontend.
/cerbere_rag/
├── ingest_neo4j.py # Script pour traiter et ingérer les données dans Neo4j.
├── extract_wiki_to_html.py # Script pour exporter les pages Confluence en HTML.
├── model/
│ └── index.cypher # Requêtes Cypher pour créer les index et contraintes.
└── rag_app/
├── main.py # Cœur de l'application : API FastAPI.
├── retrieval.py # Logique de recherche et de récupération depuis Neo4j.
├── llm.py # Configuration du LLM (Qwen) et du prompt.
├── audio_transcriber.py # Module de transcription audio (Whisper).
├── config.py # Fichier de configuration centralisé.
├── templates/
│ └── index.html # Fichier HTML de l'interface utilisateur.
└── static/
└── style.css # Fichier de style CSS.
Problèmes rencontrés
Templating jinja2
J’utilise grok pour coder et vscode+ gemini comme IDE
La page html contient des macros jinja2.
Grok s’est trompé sur l’appel à la fonction qui transforme index.html avec jinja.
J’y ai perdu 3 heures
from fastapi.templating import Jinja2Templates
templates = Jinja2Templates(directory="templates")
@app.get("/", response_class=HTMLResponse)
async def home(request: Request):
return templates.TemplateResponse("index.html", {"request": request})J’ai repris cette partie avec chatgpt puis gemini. Aucun n’a trouvé.
J’ai fini par ouvrir un google pour chercher la doc de la librairie et le prototype avait changé avec la version
from fastapi.templating import Jinja2Templates
app = FastAPI(title="RAG Confluence - Qwen3.5")
BASE_DIR = Path(__file__).resolve().parent
app.mount("/static", StaticFiles(directory=str(BASE_DIR / "static")), name="static")
templates = Jinja2Templates(directory=str(BASE_DIR / "templates"))
@app.get("/", response_class=HTMLResponse)
async def home(request: Request):
print(type(AVAILABLE_ROLES))
print(AVAILABLE_ROLES)
return templates.TemplateResponse(
request, "index.html", {"roles": AVAILABLE_ROLES}
)
Le modèle pour convertir audio → texte
J’avais demandé à Gemini de fabriquer la route audio à partir d’un exemple qui traduisait une chanson française en texte
Quand j’appuyais sur le micro, il me sortait une phrase avant que je ne parle 😉
En précisant le français comme langue, les anglissismes sont traduits en texte n’import comment
Exemple: PI s’affiche pi aille, on passe sur onboarding etc…
Solution simple et qui marche très bien… Ne pas préciser de langue et laisser whisper se débrouiller.
Ca marche tellement bien que j’hésite à faire une autre application sur le thème de dictée vocale.
La gestion des cartes graphiques
J’ai mis un certain temps à comprendre pourquoi le modèle tenait en mémoire sur ollama et ensuite mettait 30 secondes à répondre dans l’application.
Premier axe: le mode thinking.
Par défaut, qwen est en mode agent, vous assistez à un ensemble de réflexions métaphysiques avant d’avoir une réponse (genre le client demande ça, c’est peut être pas vrai, peut être je devrais répondre avec humour, peut être ça va le vexer, je synthétise les 25 réponses possibles, laquelle je choisis,…) , ce qui allonge sacrément les temps de réponse.
Deuxième axe: Bah le modèle occupe trop de mémoire et tourne sur le CPU
Là encore, j’ai perdu un max de temps avec Grok et gemini. Le point de départ est de constater que le cpu est utilisé à 100%.
Je vous donne la réponse… Le nombre de tokens (c’est ce qui fixe la mémoire de votre RAG) !
La doc dit que qwen3.5 supporte 256k de tokens; j’avais mis 120000. Sauf que ça consomme pas mal de VRAM. Avec 12go de RAM et un embedded qui prend 2Go. j’arrive après plusieurs essais à max_tokens=3000.
Et là: miracle ! ça répond à la seconde.
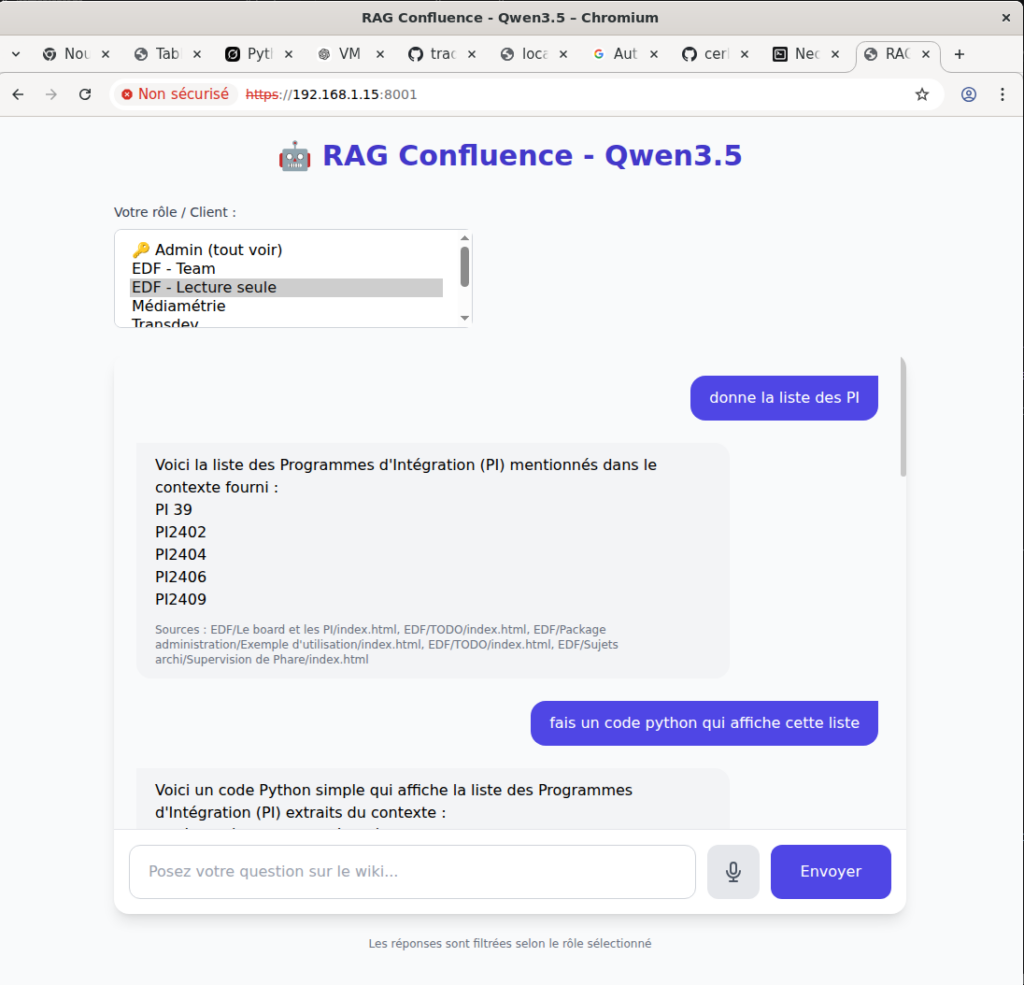
Une capture d’écran
Synthèse
L’objectif était de montrer comment monter son propre RAG et d’adresser un sujet épineux: « gérer la confidentialité des documents ». Ici, j’ai utilisé Neo4j et chaque document a une relation vers une liste de roles.
Dans la vraie vie, le rôle serait issu d’un microsoft active directory par exemple (ou EntraId maintenant)
Ainsi même en faisant de l’injection de prompt, vous ne pourrez pas accéder à des infos hors de votre groupe.
!!! That’s all folks !!!