Je suis allé à cette nouvelle édition du salon bigdata, évènement incontournable.
Nous sommes à un tournant, je remarque que la plupart des éditeurs historiques du BigData sont absents. Il y a deux trois ans, tout le monde présentait chatgpt dans son application, depuis, il est plutôt question d’être ouvert sur la plupart des LLM, claude, mistral, openAI …
Dans cette édition, on trouve essentiellement des applications SaaS hébergées chez les 3 providers AWS, GCP, Azure.
Côté éditeurs, il y avait Snowflake, Oracle, Cloudera, OVH, Azure…
J’ai trouvé intéressante l’approche Oracle qui a mis un panneau sur son offre cloud (souvent méconnue mais que j’ai testée depuis 2 ans) et un stand spécial simulateur de F1.

Après un premier tour de salon, je suis passé écouter le REX de AG2R, groupe d’assurance.
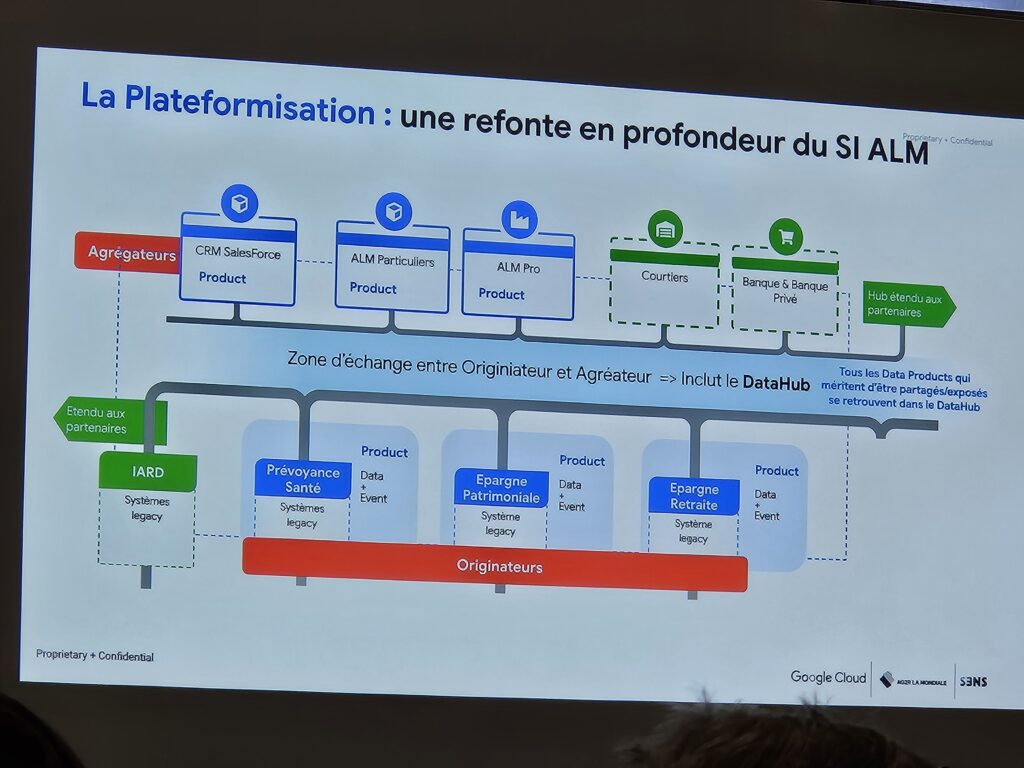
C’était très intéressant et je mesure la maturité des entreprises dans le bigdata. Maintenant, l’entreprise se réorganise en profondeur, alimente un datahub en fil de l’eau (change data capture sur les bases sources), crée un système fédéré pour que chaque domaine soit autonome et gère la sécurité par data sharing. Ici la réorganisation en domaines
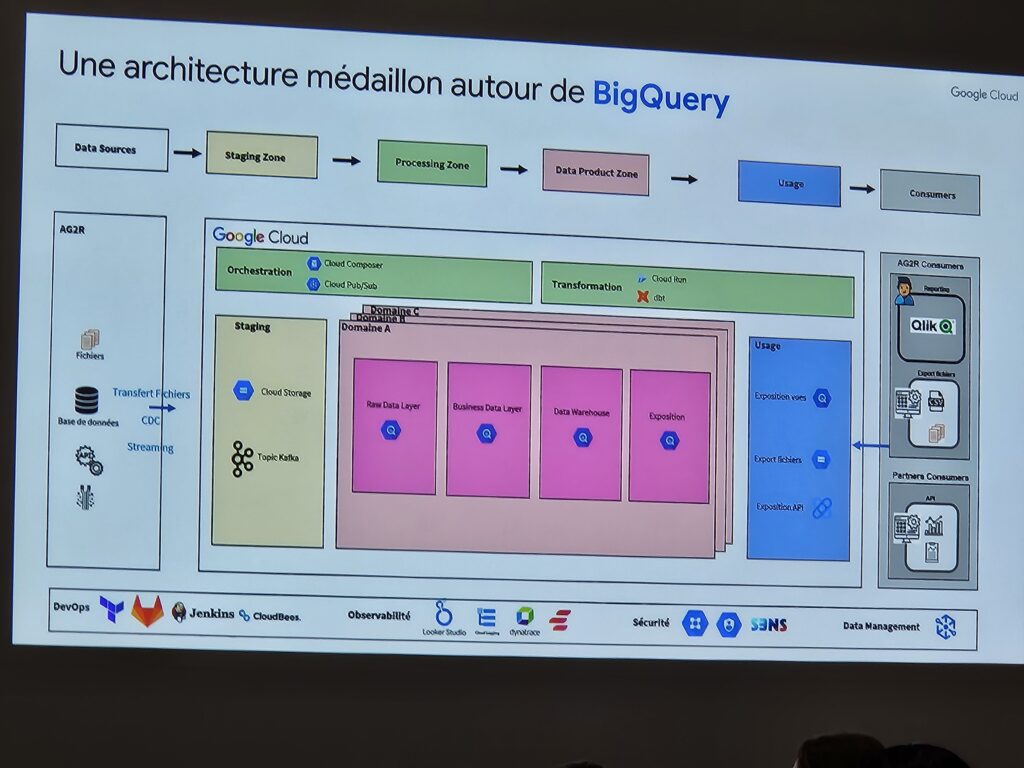
Et là, l’architecture adoptée pour la plateforme d’échange. Le choix du cloud s’est porté sur GCP et BigQuery
Ce salon a été l’occasion de retrouver d’anciens collègues, dont quelques uns animaient des présentations
Ici Andréa, un datascientiste que j’ai connu à la banque postale, présentant des travaux de recherches avec ProbaYes, une société de datascience, située à Grenoble et détenue majoritairement par le groupe La Poste, que je connais depuis longtemps.
Le sujet est sur l’automatisation des réponses et de la gestion des organismes de gestion en contact avec la caisse des dépôts (le client final);


J’ai retrouvé Artik Consulting, mon ancien responsable quand je travaillais pour la caisse des dépôts et comme le monde est petit, ils se trouvent qu’ils travaillent ensemble sur une mission
Le sujet, présenté par Kim, un ex collègue est sur la conformité avec les lois européenne sur l’utilisation de l’IA.

Pour finir ce salon nous sommes allés à la rencontre d’un joyeux groupe de belges, le produit TIMI.
Au départ, c’est un produit de datascience, d’analyse de données qui est capable de façon très performante de gérer en local sur un PC des milliards de lignes. Le produit existe depuis 15 ans et il y a eu quelques « pivotages » comme la transformation en plateforme d’échange, des missions de recherche, et le meilleur pour la fin, une migration Talend vers Timi.
Cette dernière orientation pourrait bien m’intéresser pour décommissionner Talend.
Spéciale dédicace à Frank Vanden Berghen pour sa perspicacité dans ses réponses aux questions nombreuses que lui posaient une amie.

Conclusion
Ce salon était intéressant mais je reste un peu inquiet pour la suite.
Il ne reste que des éditeurs cloud et des sociétés de services.
La plupart des autres organise des évènements spécifiques à leur domaine… elastic, confluence couchbase
Les éditeurs cloud ont aussi leurs évènements.
Les entreprises ont mûris et elles ne sont plus en recherche de solutions et de service; c’est même l’inverse. En France dans la lignée des référencements, il y a une architecture groupe qui se dessine avec ses choix de produits et cela ferme clairement la porte à la nouveauté, le test, la confiance. Sur décision groupe, je me retrouve à chercher des solutions pour décommissionner des produits, changer l’architecture et définir une Roadmap pour être conforme à leur stack.
Longue vie au BigData