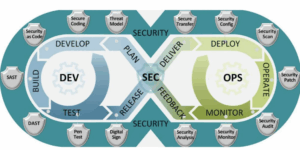
Je suis toujours en réflexion quant au contenu d’une distribution Hadoop.
Certes presque toutes les entreprises font du bigdata mais beaucoup se posent des questions sur les futurs coûts de licences et sur l’intérêt de ce cluster.
Je suis parti de l’idée que la stack devait être beaucoup plus ouverte et permette d’autres use cases.
La plateforme vient donc avec elastic search, janus (base graphe), dataiku en mode mono licence, mongodb, cassandra, druid, postgres, cassandra, mongodb, kafka…
.
Je souhaite fournir des datasets en provenance d’open data.
- Les sociétés
- Le suivi des décès
- les villes et code postaux
- des données wikipedia pour améliorer l’entraînement de modèles
J’ai avancé sur wikidata, une indexation de wikipedia qui vient avec un langage SparQl.
Avez-vous des idées d’utilisation de Wikidata ?